






 This Industry Viewpoint was authored by Aniket Khosla, Spirent’s Vice President of Wireline Product Management
This Industry Viewpoint was authored by Aniket Khosla, Spirent’s Vice President of Wireline Product Management
For a technology limited to sci-fi movies just a few years ago, artificial intelligence (AI) is suddenly everywhere. In a McKinsey survey conducted in April 2024, less than a year after ChatGPT and other first-generation tools debuted, 55% of respondents said they were already using AI. More than two thirds reported that they were planning to increase AI investments.
Ready or not, AI is about to bring big changes to every industry. And nowhere will these changes be felt more quickly or directly than in the data centers tasked with processing AI workloads.
Hyperscale operators are already investing in huge numbers of specialized central processing units (CPUs), graphics processing units (GPUs), field-programmable gate arrays (FPGAs), and other “xPU” accelerators to build out AI clusters. Now, they need to connect those clusters at speeds and scales that far exceed what they can achieve with conventional infrastructures. How they’ll do it is still an open question, though one that networking vendors are working furiously to help answer.
What’s so different about AI workloads that pushes traditional data center networks to the breaking point? And how are hyperscalers and vendors responding? Let’s take a closer look.
New Applications, New Network Demands
You’d think that no one would be better prepared to meet the demands of emerging AI applications than the companies running the world’s largest data centers. Yet it’s hyperscalers sounding the alarm about the limitations of current infrastructures and urging vendors to accelerate timetables for new solutions. To understand why, let’s review what happens inside a typical AI cluster.
AI workload processing encompasses two distinct types of work:
- Model training: In this phase, AI clusters ingest huge data sets for AI models to train on. The model analyzes relationships between inputs and outputs in the training data and, over time, learns how to classify data and make predictions with ever-greater accuracy.
- Inferencing: In this phase, AI models apply their training to new data. This can encompass a variety of real-time scenarios, such as AI chatbots responding to customer service queries, large language models (LLMs) generating images from text prompts, or AI vision applications monitoring live video in manufacturing plants to identify production flaws.
Both training and inferencing can involve extremely compute- and data-intensive workloads, demanding thousands of specialized processors and the ability to support thousands of synchronized jobs in parallel. It’s in the inferencing phase, however, where the need for extreme speeds and throughput is most urgent and where conventional networking approaches break down.
Compared to training, inferencing generates five times more traffic per xPU and requires networks with five times more bandwidth. Given the real-time nature of many AI inferencing scenarios, workloads must also progress through many nodes as quickly as possible, demanding extremely low latency at massive scales. After all, depending on the application, any lag in an AI cluster’s response could lead to timeouts, poor customer experiences, expensive errors, or worse.
These are not hypothetical concerns. According to Meta, 33% of current AI workload processing time is spent waiting for the network. And that’s for current AI models, which are effectively still in their infancy and growing 1,000x more complex every three years.
Scaling Data Center Networks
Data center operators can’t meet exploding AI application requirements by simply adding more servers and fiber runs as they have in the past. They need new architectural approaches, especially for inferencing workloads that can require tens of thousands of xPUs processing billions—soon trillions—of dense parameters. Here, operators are deploying dedicated back-end infrastructures and adopting the latest, fastest networking technologies as quickly as vendors can deliver them.
Indeed, customer demand for AI is so great, hyperscalers have no choice to but to start upgrading infrastructures now, even if that means implementing new high-speed networking silicon long before standards are finalized. At the same time, there is still no consensus around the optimal back-end cluster design or network technologies to adopt. Google, Microsoft, and Amazon, for example, are all currently pursuing different strategies.
Fortunately, we’re starting to get clues about how the market for AI networking technologies will ultimately shake out. In back-end networks where operators face the most urgent need, the transition to next-generation interfaces is already well under way, and according to Dell’Oro Group, nearly all ports will be 800G by 2027. For front-end connectivity to AI clusters (which initially will be driven by the need for high-speed data ingestion), upgrades will progress more slowly. Dell’Oro expects one third of all Ethernet ports will be 800G or higher in the same timeframe.
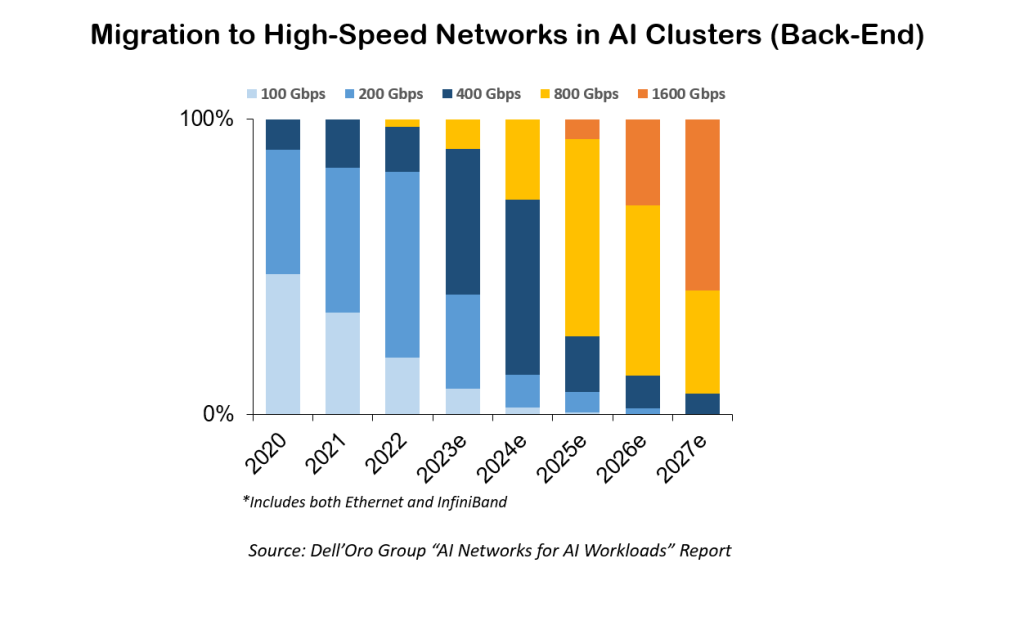
Which interface technology hyperscalers will prefer for front- and back-end networks is also still an open question—one that likely won’t have a clear answer anytime soon. Here, operators can choose high-speed Ethernet, with its broad industry acceptance and the economics that come with standardization, or proprietary technologies like InfiniBand that deliver lossless performance. Dell’Oro expects Ethernet to dominate front-end connectivity, while back-end networks will include both Ethernet and InfiniBand for the foreseeable future.
Looking Ahead
Which technologies and architectural approaches will the industry ultimately settle on to meet evolving AI requirements? For now, no one can say for sure, for two big reasons.
First, these questions don’t have a one-size-fits-all answer. Whether an operator chooses Ethernet, InfiniBand, or both will depend on multiple factors including size and number of clusters, mix of AI applications, preference for standardized versus proprietary technologies, comfort with a given technology’s roadmap, and other considerations. Additionally, AI is evolving so quickly, we just don’t know exactly what the future will hold. This uncertainty poses significant challenges for operators, who risk making the wrong calls—and potentially finding their infrastructure obsolete within just a few years.
As always, the best way to mitigate that risk—especially when implementing standards that are still being defined—is via rigorous testing. As hyperscalers and vendors speed next-generation solutions through development, they’ll need next-generation tools to test and validate them. For vendors, the ability to emulate hyperscale AI infrastructures (instead of attempting to rebuild them in the lab) will also be essential. Fortunately, test and emulation providers are innovating alongside vendors and are ready to address these needs.
While many questions remain, there’s one we can answer definitively: However quickly vendors and hyperscalers can implement new AI-optimized infrastructures, customers will be ready to use them.
If you haven't already, please take our Reader Survey! Just 3 questions to help us better understand who is reading Telecom Ramblings so we can serve you better!
Categories: Datacenter · Industry Viewpoint · Software · Telecom Equipment
Discuss this Post