






This Industry Viewpoint was authored by Prashantkumar Maloo – Technical Architect, Prodapt Solutions
Today, most Digital Service Providers (DSPs) use Artificial Intelligence (AI) in several vital processes like network fault prediction, personalized offer simulation, streamlined customer services, etc. But despite spending on the AI initiatives, DSPs continue to face numerous ML operational challenges. Some major challenges encountered by the DSPs in their ML pipeline and operations are as below:
- Inefficient retraining and deployment of the ML models to accommodate the data drift
- Lack of standard change management process to address the change request in ML pipeline
- Lack of in-depth visibility about the model’s performance as it interacts with real-world events
These challenges limit the ability of the DSPs to realize the potential business value of the ML use cases. To overcome this, DSPs need to shift from the current method of ML model management and adopt an ML Operations (MLOps) approach. It helps to automate and monitor the entire machine learning lifecycle, enabling faster time to production of ML models. Serverless MLOps is a further advancement to this, which provides add-on benefits to ease the adaptability of AI/ML in the day-to-day operations of DSPs. While most forward-thinking DSPs have started embracing MLOps, implementing it successfully and achieving the best results is not easy. This article elaborates on the key levers of the MLOps approach to reduce retraining time and time-to-market of AI/ML models by 70%, with Personalized Offer Simulation (next best offer recommendation) as a sample use case.
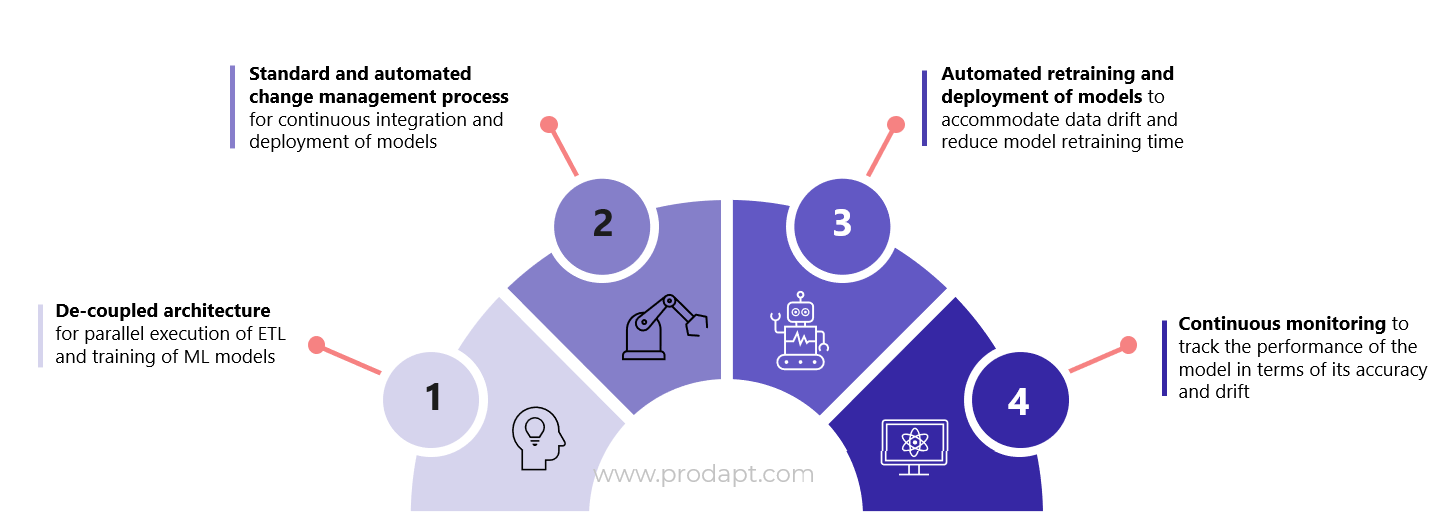 Fig.1 Key levers of MLOps approach
Fig.1 Key levers of MLOps approach
The four key levers of the MLOps approach that enables the DSPs in accelerating the AI initiatives are detailed below.
1. Decoupled architecture for parallel ETL and training of ML models
Due to coupled systems and resource dependencies, DSPs struggle to scale their ML pipeline for new use cases. By implementing a decoupled architecture, the components from the existing pipeline can be reused for different ML use cases. E.g., the output of ETL1 from offer simulation can be reused for churn analysis. It also enables parallel ETL execution and model training, thus saving time, effort, and cost for DSPs.
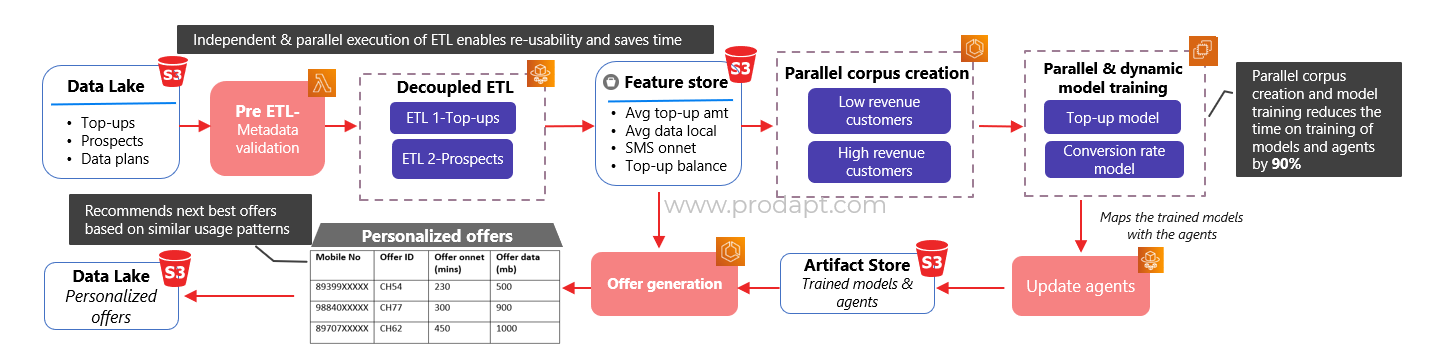 Fig.2 Sample decoupled architecture for Personalized Offer Simulation & Recommendation
Fig.2 Sample decoupled architecture for Personalized Offer Simulation & Recommendation
Recommendations
- Implement serverless services like AWS Lambda or Google Cloud Functions to validate the metadata and ensure that the necessary configurations are met before proceeding to ETL. It avoids validation issues during the model run, thereby reducing time and cost
- Develop an AWS Glue or Google Dataproc homologation script to handle the changes while transferring data from the Data Lake to the ML engine
2. Standardized and automated change management process
In a typical ML model operation, DSPs find it difficult to set up a pipeline where the changes are continuously built and made ready for production. Standardizing and automating the change management process enables continuous deployment of models with reproducibility, security, and code version control. For instance, standard and auto-change management process helps the DSPs to accelerate the rollout of data plan model for new geography customers by 60-70%.
Recommendations
- Implement services like
Kubeflow pipelines or AWS Cloud Development Kit (CDK) for defining the resources in familiar languages. It auto-creates an equivalent YAML file, resulting in easier maintenance of the huge MLOps codes
3. Automated retraining and deployment of ML models
Validate the data quality and detect the data drift
DSPs face frequent data drift due to the constantly changing customer behavior. About 80% of the data drift occurs due to unexpected events or occasions. To detect the drift, develop a pipeline that pulls the previous month’s data usage and generates projections for different users. Implement an anomaly detection model to forecast the data plans. Track the daily data usage and validate it with the forecasted range. E.g., when the data usage is not in the range of 300-500 MB, consider it as an anomaly. When the number of anomalies exceeds the defined threshold (e.g., 20% of the total data), retrain the ML model to accommodate the data drift.
Build an automated retraining and deployment pipeline
Resolving the data drift by retraining the model manually is cumbersome and time-consuming. Hence, build an automated pipeline that retrains the model based on the new data set. Further, it should identify and send an automated mail summarizing the change of features due to data drift, enabling the DSPs to decide the next course of action and improve accuracy.
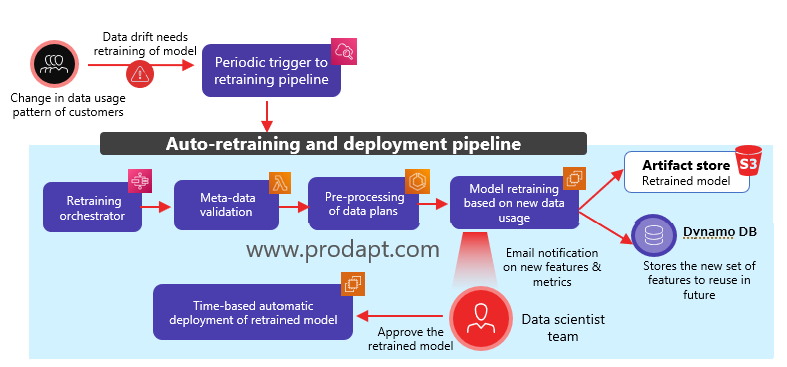 Fig.3 Sample auto-retraining and deployment of models to accommodate the drift in customer’s data usage
Fig.3 Sample auto-retraining and deployment of models to accommodate the drift in customer’s data usage
4. Continuous monitoring
The DSPs’ machine learning models often interact with various real-world events which makes the model’s predictions and accuracy degrade over time. Hence, leverage a monitoring pipeline to track and capture the performance of the predicted offers. Continuous monitoring provides the DSPs with real-time and in-depth visibility of the models and helps to identify potential issues before they impact the business.
In Conclusion
By implementing the four levers explained in this article, DSPs can experience the following benefits:
- 70% reduction in model retraining and deployment time
- 50% reduction in data pre-processing and model prediction time
- 50% OpEx savings due to decoupled systems and dynamic spawning of resources
- ~75 to 85% consistent improvement in the baseline accuracy of the ML use cases
I appreciate the efforts of my colleagues Dinesh Singh GC, Skanda Gurunathan R, and Priyankaa A for their contributions and continuous support in writing this article.
Contributing Authors
 Prashant Maloo, System Architect, Prodapt
Prashant Maloo, System Architect, Prodapt
Prashant Maloo has exclusive experience in Telecommunications building products, solutions, and niche technology teams. He has a keen eye on introducing new technology to solve telco problems and has helped global telco’s achieve new tech adoption through large scale digital transformations. Currently he is focussed on AI adoption and addressing the Cybersecurity needs of the Cloud Network Service domain.
Prashant is a System Architect / Director – Next Gen at Prodapt, a two-decade-old consulting & managed services provider singularly focused on the Technology, Media, & Telecommunications (TMT) industry that helps clients transform their IT, products, operations, and networks to meet their strategic objectives. Prodapt’s business consultants enable DSPs on their transformation journey at several layers, including cloud, customer experience, business outcome focussed initiatives, CapEx, and OpEx optimization programs.
If you haven't already, please take our Reader Survey! Just 3 questions to help us better understand who is reading Telecom Ramblings so we can serve you better!
Categories: Artificial Intelligence · Industry Viewpoint
Discuss this Post